



























- Optimizing Neural Networks for Edge Devices: The Power of Deep Neural Network Pruning
- Understanding Deep Neural Network Pruning
- The Importance of Edge Devices to Neural Networks
- Benefits of Deep Neural Network Pruning
- Case Studies in Deep Neural Network Pruning for Edge Applications
- In Summary: Best Practices for Implementing Deep Neural Network Pruning
Key Takeaways:
- Pruning of deep neural networks enables their efficient use on edge devices
- The most relevant and important data and workloads are prioritized
- Optimized models, as a result of deep neural network pruning, are ideal for real time processing, sustainable AI and efficient computing
- It can also ensure AI insight generation is secure and compliant
Optimizing Neural Networks for Edge Devices: The Power of Deep Neural Network Pruning
Neural networks - and deep neural networks in particular - are driving machine learning that is closer than ever to the thought processes of the human brain. Their ability to learn and drive decisions from data makes them ideal candidates to use the information gathered by edge devices.
These edge devices, from smartphones to IoT sensors, can collect so much data for neural networks that a level of refinement and focus is. This process is called deep neural network pruning, and this blog explores how it works and why it’s so beneficial.
Understanding Deep Neural Network Pruning
Deep neural network pruning is the act of removing parameters from neural network models that aren’t important to its successful operation. The theory mimics the principle that the brain turns down use of connections between neurons that aren’t needed, to devote more energy to the more important ones. In practice, this means reducing the weights (and not the biases) of the parameters, in order to reduce the size of the Generative AI model for example, and make its function and findings more efficient.
In the context of edge devices, deep neural network pruning is important because those devices tend to be relatively constrained in terms of their capacity across processing, latency, memory and network bandwidth for model deployment. Filtering unnecessary workloads ensures the most important data processing takes place, maximizing the efficiency and results of the model.
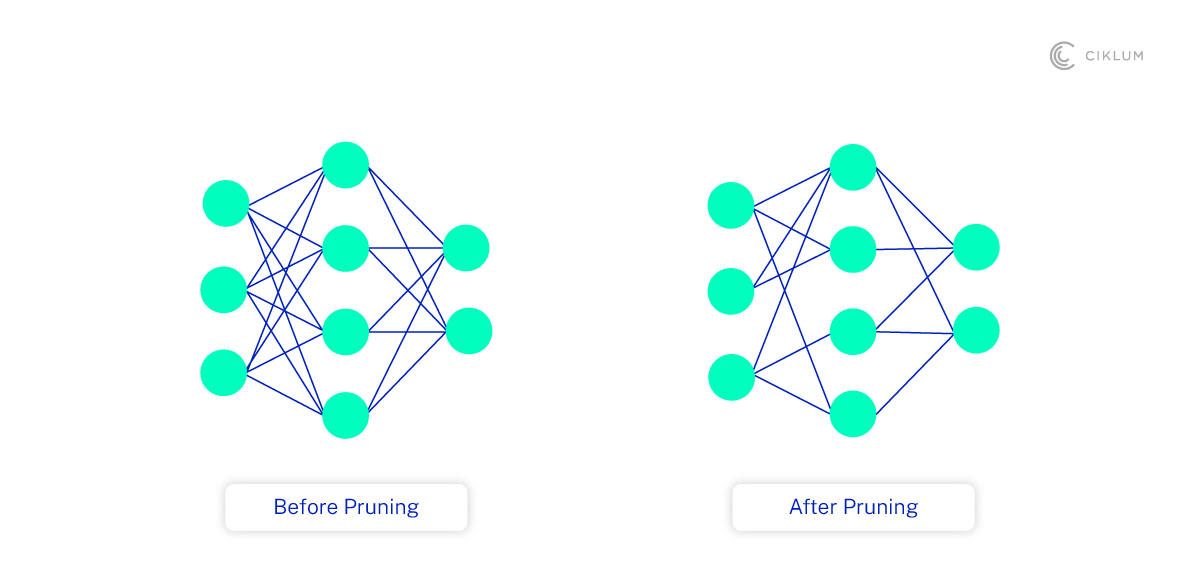
The Importance of Edge Devices to Neural Networks
Edge devices process data closer to where it’s generated, rather than sending additional workload to central servers or cloud-based data centers. These devices include (and are by no means limited to) smartphones, IoT devices like cameras and thermostats, and even microcontrollers in modern cars.
These devices are extremely beneficial for modern computing architectures. They can reduce demands on bandwidth and latency, support greater insights and real-time decision-making, cut energy consumption, and improve data privacy and security. But as mentioned in the previous section, edge devices often aren’t suited to the demands of neural networks like high storage space volumes, intensive compute power and large memory requirements.
With the help of deep neural network pruning, therefore, edge devices can support important functions based around neural networks, including face and speech recognition, autonomous vehicles, healthcare wearables, augmented reality and more.
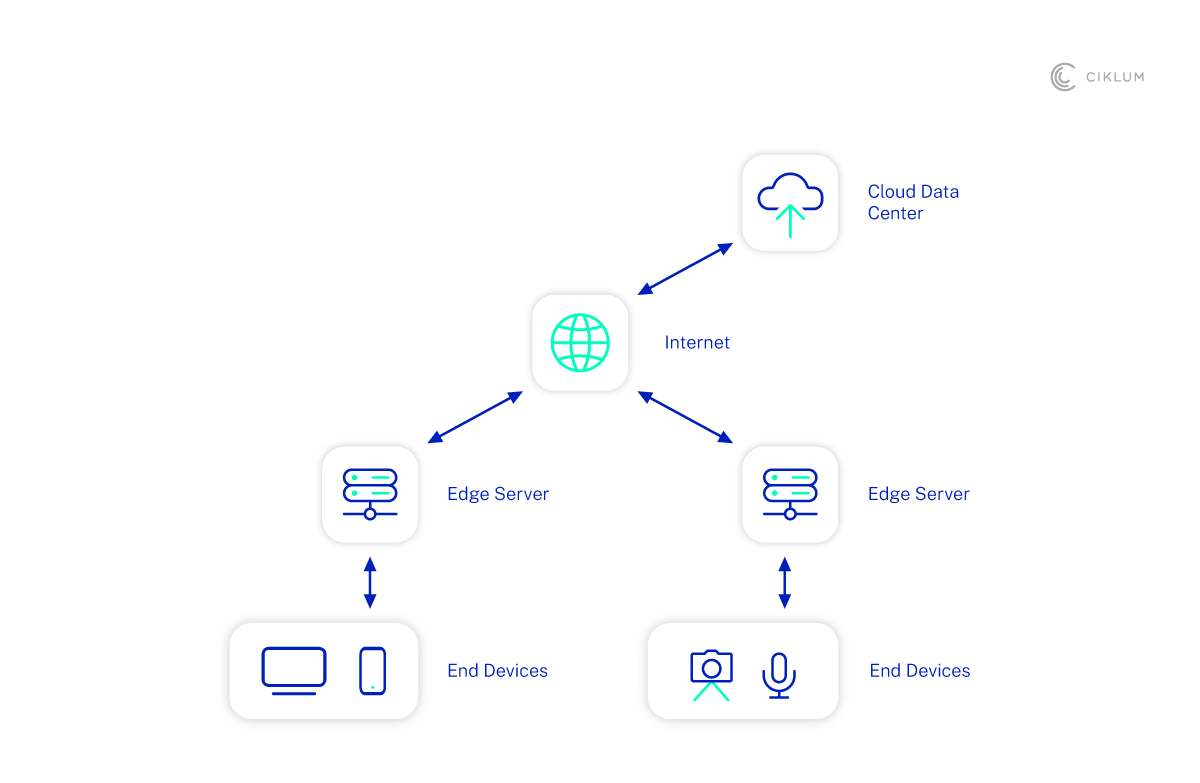
Benefits of Deep Neural Network Pruning
Computing Efficiency
Deep neural network pruning enables a significant reduction in the size of neural networks, which in turn reduces the demand for memory and storage. This approach can reduce model weights by more than 50% (and in our experience, can deliver reductions of up to 80%) while maintaining a less than 1% drop in accuracy. Not only does this relieve the pressure on edge devices, but it also reduces the cost and demand on requirements at the center of the network, whether in the cloud or on-premise.
In turn, this makes neural networks more practical to deploy in a wider range of settings where RAM and flash storage are limited. It also speeds up execution time through faster inference and lower latency, which is especially critical in applications like autonomous vehicles or AR which operate in real-time.
Eco-Friendliness
The use of machine learning algorithms, and artificial intelligence more widely, is coming under increasing social and regulatory scrutiny for its impact on the environment. Processing and transferring large volumes of data come with energy and emissions implications in training and inference, which deep neural network pruning can address by stripping out unnecessary workloads.
Ensuring AI runs on edge devices rather than on cloud platforms supports this further by cutting out more data transmissions and lowering the energy consumption of the cloud, simultaneously lowering the cost of AI in the process.
On-Device AI Capabilities
If edge devices are able to complete AI tasks independently, then the need for a fast and stable Internet connection to transfer data is removed. This is especially useful in supporting functionality offline: for example, face and image recognition and real-time processing can take place in remote and rural areas. The latency and lead time of waiting for responses from the cloud can also be removed.
Additionally, privacy and security can be enhanced as sensitive data (such as biometric information and medical records) can stay on the device in question, minimizing its potential attack surface. This can be instrumental in not only securing that data, but also in maintaining compliance with key privacy regulations like GDPR and CCPA.
Case Studies in Deep Neural Network Pruning for Edge Applications
Deep neural network pruning is already being applied to good effect in a range of industries where neural networks are supported by edge devices.
- PruneFL demonstrates effective model pruning for federated learning on edge devices, reducing training time while maintaining model accuracy through adaptive parameter pruning.
- A cloud-edge collaborative framework achieved 82-84% lower latency with minimal accuracy loss through specialized pruning methods and efficient feature coding between cloud and edge devices.
In Summary: Best Practices for Implementing Deep Neural Network Pruning
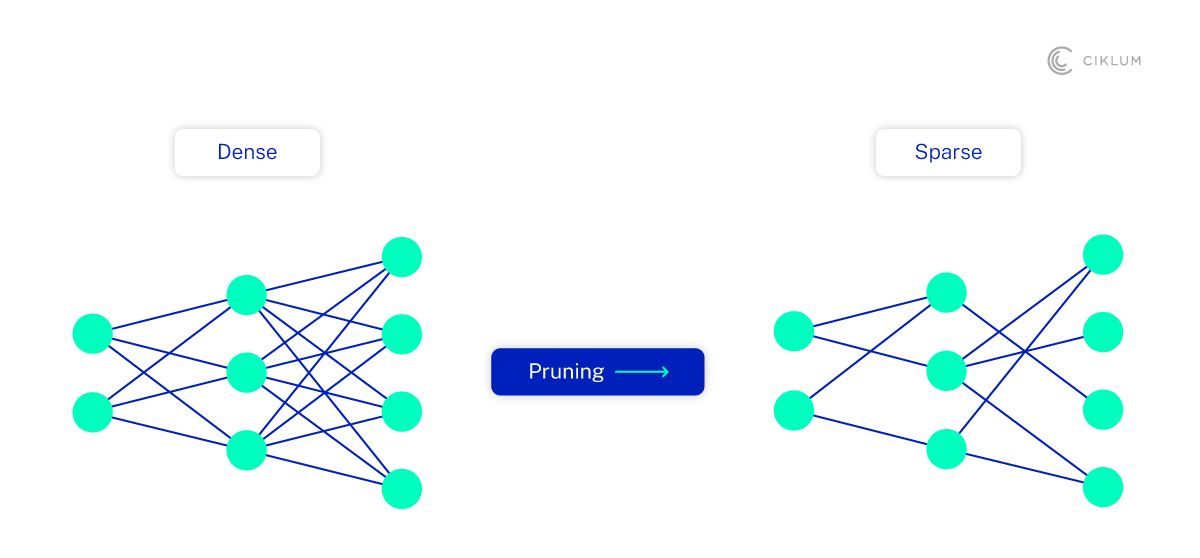
Getting deep neural network pruning right is important to maximize the benefit of edge devices and the insights they can generate for neural networks. It may sound very complicated, but there are several ways to do it adequately, including:
- Random Pruning: removes weights or units (like neurons/filters/whole layers) randomly
- Magnitude-Based Pruning: removes the lowest-magnitude weights
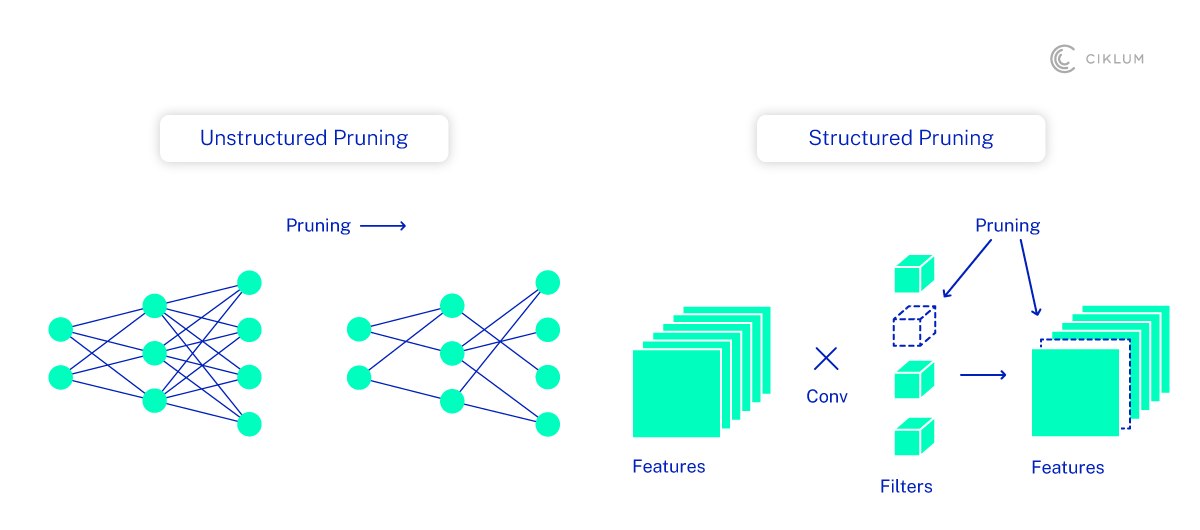
- Structured Pruning: removes entire units, (like neurons/filters/whole layers) instead of only weights
- Sensitivity-Based Pruning: removes weights or units based on impact on loss/accuracy
Examples of some pruning techniques are shown in the following figure:
If you feel you need support in weight pruning, then the help and advice of an expert AI and machine learning partner can be invaluable. Explore the Ciklum approach to data and AI today, then contact our team to find out more.


By Tomas Kliment

Senior Data Scientist
Tomas Kliment is a Senior Data Scientist at Ciklum. He builds practical machine learning and automation solutions that help teams turn data into meaningful, usable outcomes. With a background in Python development and hands-on experience across deep learning, analytics, and model development, he focuses on creating systems that are reliable, explainable, and ready for real-world conditions.
Blogs
Discover Similar Insights

Strategies for Integrating XR Experiences into Existing Customer Journeys
Learn More
AR/VR Trends and Predictions For 2025 & Beyond
Learn More
Transform Your Retail Experience with Advanced AR Solutions
Learn More
8 Benefits of Extended Reality for Modern Manufacturing Processes
Learn More